iTELL Data Privacy: How we use third-party AI and how we don't

By Langdon Holmes, Chief Technology Officer
The most sensitive learner data in iTELL are constructed responses and the scores they receive. This data never leaves our own infrastructure. Course materials and conversational dialogue do go to Google's Gemini API, under enterprise terms that prohibit any training use and never carry the learner's identity.
Here's the actual flow, by data type, with the contracts to back it up.
What goes where
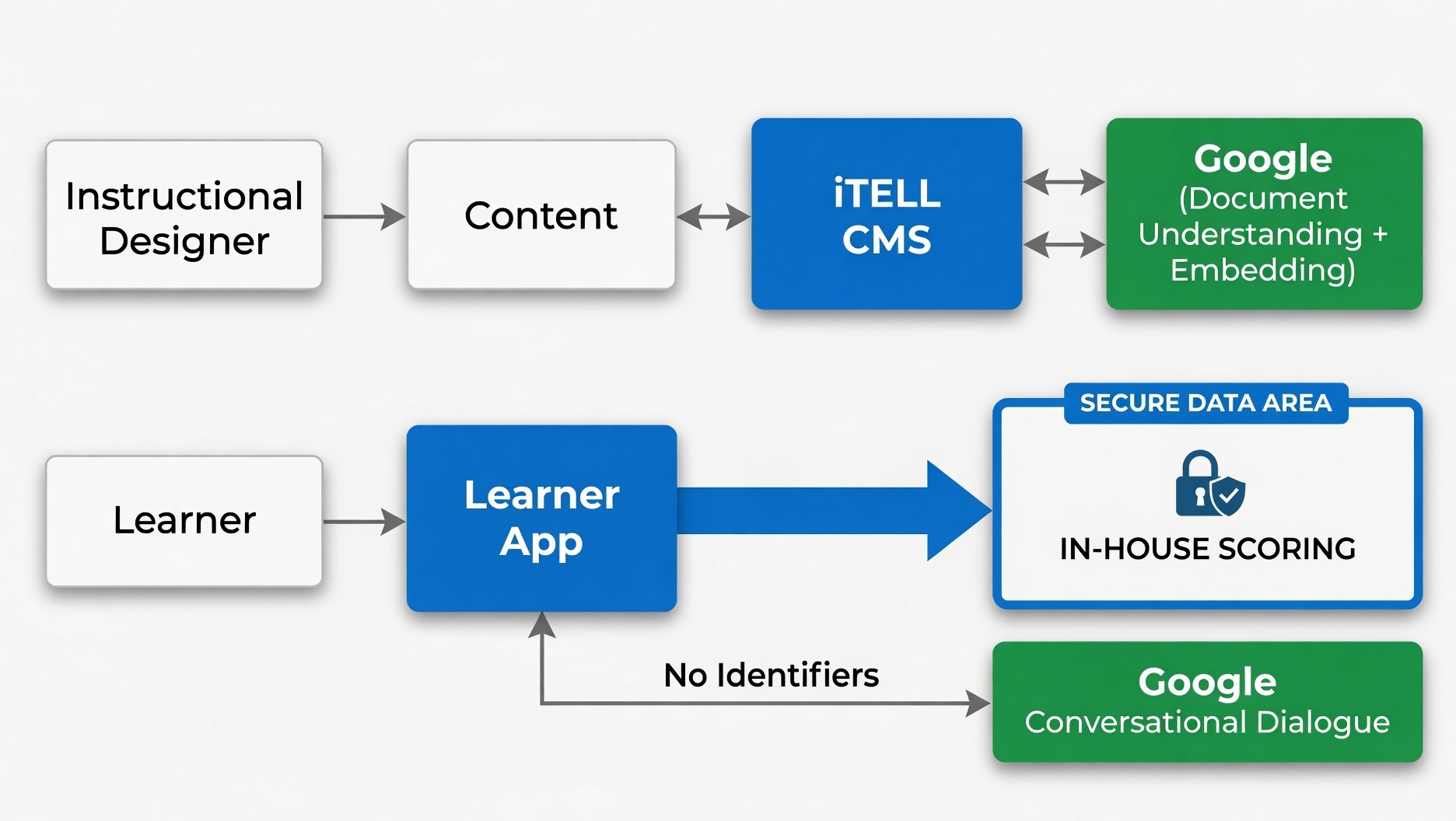
When you upload a manual, SOP, or certification prep PDF, iTELL processes it with Gemini for document understanding — parsing structure, extracting content, identifying the sections that become learning units. That request goes to Google's paid Gemini API, which is governed by the Data Processing Addendum for Products Where Google is a Data Processor. Under those terms, Google contractually commits not to use prompts, files, or responses to train or improve its products. iTELL itself never uses customer content for anything beyond delivering the service you signed up for. Google retains paid API traffic briefly for abuse detection and legal-disclosure compliance, as every major model provider does.
When a learner has a conversation with the iTELL chatbot, that exchange does go through Gemini, but importantly, no identifying information about the learner travels with it. Gemini sees the question and the relevant content chunk. Nothing else (no learner ID, no cohort, no progress history). The same DPA and no-training commitments apply.
The third bucket is where the answer is the simplest. When a learner submits work for evaluation, such as a summary or a constructed response, that submission and the score it receives never go to Gemini. Scoring runs on iTELL's own fine-tuned models on iTELL's own GPUs. The student's actual answer, the rubric-anchored score, and the feedback that goes back to them stay in our infrastructure end-to-end. This is the part of a learner's record that becomes a transcript entry, a remediation flag, an exam-readiness signal — and it does not leave our systems.
Why the architecture is shaped this way
This split isn't a retrofit on top of a generic AI pipeline. It reflects something we believe about where frontier models actually earn their cost.
Frontier models like Gemini are excellent at open-ended reasoning — natural dialogue, parsing a long document, pulling context together to answer a question. Small specialized models, fine-tuned on a specific task, often match or beat them at narrow scoring problems at a fraction of the cost. We have strong opinions about scoring because we've spent years studying it (see our research).
Open-ended dialogue and document understanding go to the model that does them best. Scoring runs on models we built, evaluated, and control. Identifiers don't cross the boundary. Each piece is in the place that makes the most technical sense, and the most identity-sensitive data lives on the part of the stack fully under our control.
For your security team
If you're reviewing iTELL on behalf of a program manager, here's where to look:
- iTELL's Privacy Policy, which names our sub-processors and describes our AI data handling
- Google's paid Gemini API data-use terms
- Google's Data Processing Addendum
For a detailed data-flow diagram, our customer DPA, or a direct answer to any specific question, email hello@itell.ai and we'll route you to the right person.
Ready to see what your learners experience? Book a demo.